Goal-Oriented Action Planning (GOAP) AI
Project Description
A University Solo Project for the specialization module "Artificial Intelligence". The project
solved my research inquiry "Using Goal-Oriented Action Planning Within the Context of Turn-Based
Combat".
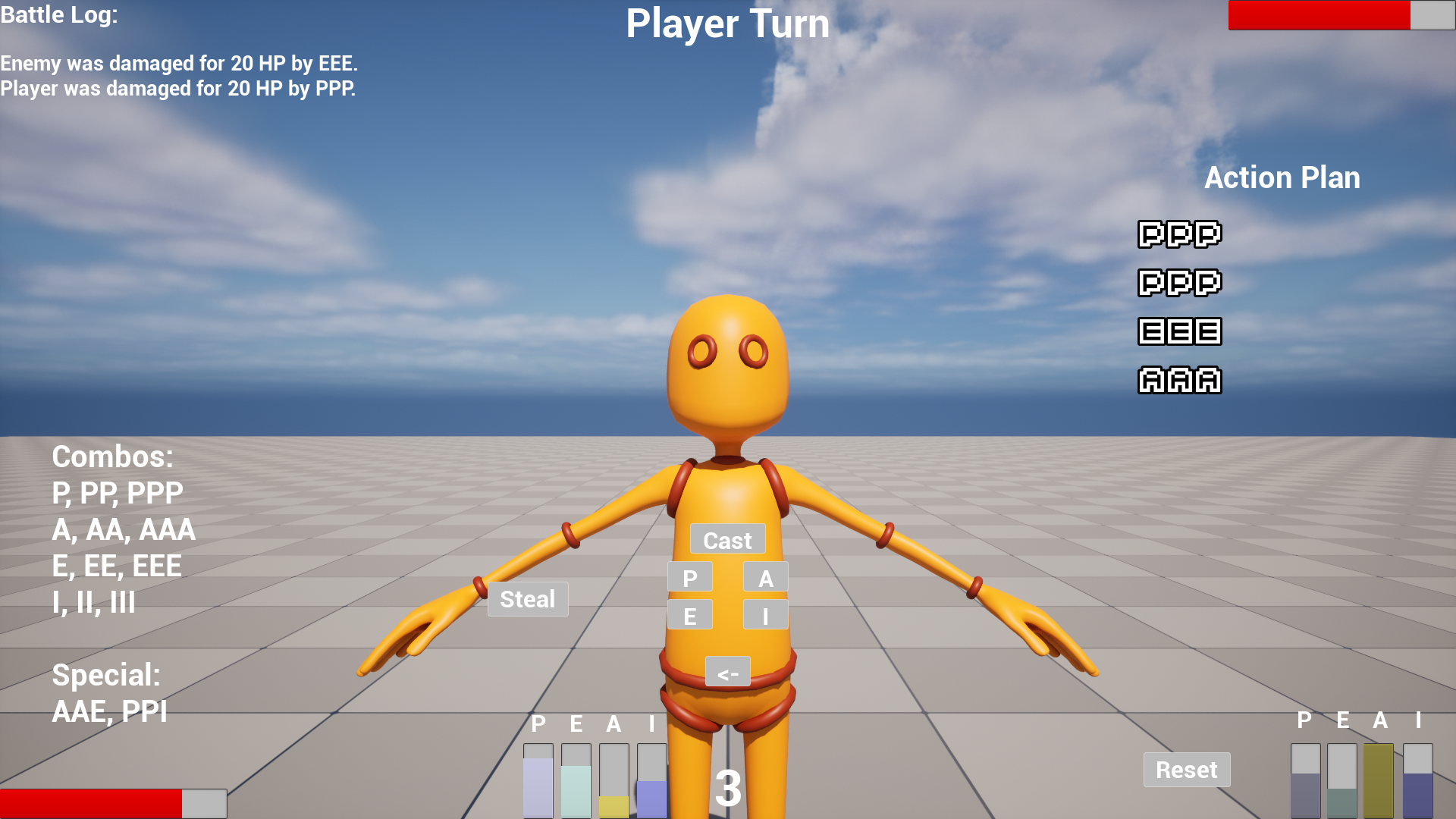
The computing artefact developed to test is a combat artificial intelligence attached
to an enemy non-player character for a small turn-based strategy game
with a focus on resource management and combo building. In this game, you
have a limited set of randomised resources that can be used to build combos to
attack an opponent. Combos vary in resource costs and which resource is required
for it to be cast you may also use more or fewer resources at random when
casting a combo creating an uncertain and dynamic environment that the artificial
intelligence must overcome. Additionally, the player is able to steal 1 unit of the
most abundant resource the opponent has but is only able to do this once. To
win you must defeat the opponent by reducing their health to 0. The combat artificial
intelligence must be able to find the optimal set of combos with the current
resources that it has on hand and perform those actions to defeat its opponent
whilst keeping itself alive.
This project that was intended to be used in the project "Azure Abyss" as a Turn-Based
Combat AI. The AI was intended to be used by the enemies in the game to generate a plan to
defeat
the player however due to time constraints I was unable to integrate it into the project.
Git Repository
Project Features
- Turn-Based Combat AI
- Goal Oriented Action Planning
- Self-Healing Plan
- Generates Optimised Plan
My Contributions
GOAP
The implementation of the Goal-Oriented Action Planning algorithm is based on the implementation
by Whyte GitHub in the game engine Unity with some
modifications,
additions and optimisations to suit the needs of the game engine Unreal, in which the artefact
was developed in, and constraints when building the tree of possible actions to reach
the agent's goal. The Goal-Oriented Action Planning algorithm and agent are implemented
as an actor component that can be attached to any actor, pawn or character game object
that requires the ability to make decisions when in turn-based combat, providing developers
with the flexibility to apply the artificial intelligence using Goal-Oriented Action Planning
anywhere as needed. The Goal-Oriented Action Planning algorithm also implements self-recovery
re-planning if the first action plan will fail to reach the goal if the environment state
does not match the predicted environment state the action plan has accounted for.
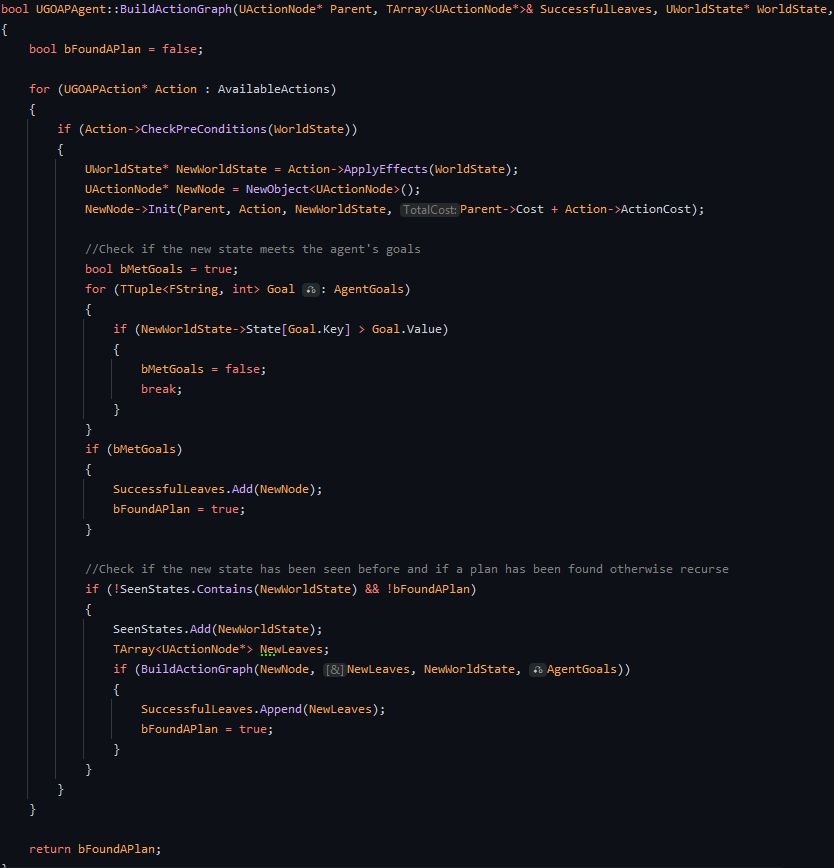
How the action plan is built in this implementation of Goal-Oriented Action Planning is that
the algorithm uses a recursive function to build a tree of action nodes that contain an action,
the current state of the environment, the parent action node and the total running cost at
that point in the tree to generate possible actions to reach the agent's goal. The algorithm
creates a list of leaves that contain the final action to an environment state in which the
agent has successfully reached its goal. The algorithm then selects the leaf with the lowest
cost and then works its way back up the tree to the root node to generate the final action
plan. This is then executed by the agent to reach its goal.
One of the critical optimisations of the Goal-Oriented Action Planning that was developed
when the algorithm builds the tree is that it sorts the actions based on their weighted costs.
This allows the artificial intelligence agents to be able to make complex decisions based on
the hierarchy of actions to fulfil the agent's goals. The algorithm considers the current state
of the game and the actions available to the agent before deciding on the most efficient
course of action. As a result, the agent will always select the action that will get it closer
to
accomplishing its goals.
Another critical optimisation of the Goal-Oriented Action Planning algorithm is that it uses a
hash set to store the states of the environment that have already been visited. This allows
the algorithm to avoid visiting the same state multiple times and instead focus on the states
that have not been visited yet. This is useful as the algorithm will be able to generate a more
efficient action plan as it will not have to consider the same states multiple times.